Illegitimate Children and a Widow’s Reluctance to Remarry
Posted: 03 Oct 2021 Filed under: Analysis, Land and property, Research strategy | Tags: Copeland, illegitimacy, Lincolnshire, Lown, Makeman, marriage, Moulton, Whaplode Leave a commentDave Annal’s talk, “Lying Bastards”: the impact of illegitimacy on the records that our ancestors leave behind at the Register of Qualified Genealogists conference last month (September 2021), has stimulated me to tell the story of Maria Lown’s illegitimate children.
Baptisms

1815. December 9
Betsey Makeman bastard daughter of Maria the Widow of William Lown, who was a Farmer living in the Fields below the Town. She lives in a small House in the low Fields. This woman’s moral depravity is so great, that she prefers living in a state of Adultery with one Wm Makeman, to a state of Matrimony with the same Man!!
Baptism Register. Whaplode, Lincolnshire. Findmypast

1817 April 17th
William bastard son of Maria Lown a widow, A Prostitute. Town
VIDE Dec 29th 1815 [Dec 9th]. NB. This abandoned woman might be Married but will not ! The Banns of Marriage have been published, but she prefers a state of Prostitution! Remarking or having remarked, that She is already a Whore; & can be no worse. Therefore, will even remain as she is!!! Sic malimores pravalebunt!!! She submitted to be Married in August following
S Oliver curate
Baptism Register. Whaplode, Lincolnshire. Findmypast
Given these comments what might you expect Maria’s background to be like? Do you think she was accurately described? Are you imagining her response was a potty mouthed torrent? Has pity for a poor widow stirred you? It is hard not to react to these entries, but let’s take a step back and look at the circumstances more closely.
Maria Copeland married William Lown in 1799. She was his second wife, so became stepmother to his two children, Ann, and William, from his first marriage with Sarah Watson. Maria and William Lown went on to have six children between 1800 and 1807, namely William, Moriah, Elizabeth, Snelson, Ann and Robert Snelson. William Lown died in 1812 and was buried at Holbeach, a neighbouring parish. There are no burials for any of the children indexed prior to his death, so I’m working on the basis that they had all survived to 1812.
So, at the time of becoming a widow, Maria had up to eight children to support.
Rapid remarriage, or the alternative of forming a joint household without marriage, is widely cited as an economic necessity for many widows. Does it apply to Maria?
The 1815 baptism above identifies William Lown as a farmer and residence at “Fields below the Town”. The occupation is a clue that William Lown may have owned or rented land. I have not investigated land holdings in Whaplode, but he is in the manorial property records in neighbouring Moulton.
William Lown bought a copyhold plot of 6 acres 36 perches, consisting of two fields with a messuage (house) and outbuildings, in 1805 in the Manor of Moulton Harrington, located on the former common near the hamlet of Seas End. It is about 3 miles north of Whaplode village centre. All records of the Lown family place their residence in Whaplode, which suggests that at least the house in Moulton and possibly the whole holding was rented out.
Why would a widow resist remarriage?
As a second wife, Maria was vulnerable to inheritance under primogenitor, which would have left real property to William Lown’s eldest son (aged 18). Furthermore, she was potentially vulnerable due to customs of local manors that removed dower rights. As a widow, Maria may have gained control of assets through guardianship of her children (eldest aged 12) and stepchildren (eldest aged 21).
William Lown did not leave Maria helpless. He made a will appointing her as executrix, so she had control of the Lown family property. I have not yet accessed the will at Lincolnshire Archives due to the pandemic, so don’t know the value of his estate. It does not seem that Maria would have needed to remarry through necessity straight away.
Social status is another possible reason for Maria Lown’s reluctance to re-marry. She had been a farmer’s wife. William Makeman was of lower status. The baptisms of William Makeman’s legitimate children display an advancement in his status from labourer (1818), to horseman (1819, 1822) and then cottager (1825, 1826).
What happened to the illegitimate children?
William died on 21 September 1817, just 5 months old and less than 2 months after his parents married. None-the-less curate Samuel Oliver continued his commentary in the same vein.

1817 Sept 21
William Bastard son of the Widow, Maria Lown, A prostitute
Burial Register. Whaplode, Lincolnshire. Findmypast
Betsy was acknowledged by her father and was named Betsy Makeman when she married in 1839. She married James Cooley, schoolmaster of Moulton, son of John Cooley, a farmer. This was a good match as I know from my research of the Moulton manors that the Cooley family were significant landowners. The marriage was performed by the same curate, Samuel Oliver, but without any commentary.
Why were the curate’s comments so vitriolic?
Samuel Oliver did not comment on every illegitimate birth beyond use of the term ‘illegitimate’. In the 3 years between 1815 and 1817, there were 11 baptisms of illegitimate children out of a total of 170. Apart from Maria, one other person was the subject of vitriolic comment, this time a man who had child with another woman having abandoned his wife
Maria certainly answered back. Was there dose of misogyny in his reaction? Did he think a farmer’s wife should behave differently? Did he fear that Maria might become dependent on the parish if she did not remarry?
Share this:

A Timeline Guides Research Questions
Posted: 19 Dec 2016 Filed under: Research strategy, Sue's family research | Tags: Australian genealogy, Bill Lawrence collection, emigration, research questions, telegram, timeline 2 CommentsHaving catalogued and scanned the Bill Lawrence collection, I now have a good idea of the contents, and loads of questions. So the next step is to analyse the contents further and decide which questions to investigate first.
An overview of the main events and themes revealed by the documents helps me identify and narrow down to priority questions. Main events documented include:
| Year | Event |
| 1886 | Birth of Edith May Spencer (Bill’s mother) in Surrey, England |
| 1913 | Marriage of William Henry Lawrence & Edith May Spencer (Bill’s parents) in New South Wales, Australia |
| 1915 | Birth of Gwendoline Dorothy Brown (Bill’s wife) |
| 1915 | Bill’s birth |
| 1919 | Bill’s father sent a telegram from Liverpool, England to his wife in Australia, about to embark for America |
| 1920 | Death of Bill’s father |
| 1922 | Robert Spencer & Mary Ann Marsden Spencer nee Bentley (Bill’s grandparents) voyage to Australia |
| 1925 | Bill, his mother & grandparents return to England from Australia on the Largs Bay |
| 1931 | Funeral of Arthur Spencer |
| 1940-1946 | Bill’s WWII service |
| 1946 | Bill’s National Health insurance & ID card issued, resident at Russell Road |
| 1953 | Photo of Bill & his mother |
| 1961 | Marriage of William Henry Lawrence (Bill) & Gwendoline Dorothy Meacham (nee Brown) |
Both of Bill’s parents were born in England, but married in Australia. There is nothing in the collection that documents their emigration. For me, this is the big question, or rather series of questions.

Marriage certificate. New South Wales, Australia. William Henry Lawrence & Edith May Spencer. 25 October 1913 WHL/1/2/2
Another question is what the enigmatic 1919 telegram from Bill’s father was about. I wonder if it is connected with what Bill’s father did in the First World War, of which there is also no record in this collection.

Telegram from Harry (Bill’s father) in Liverpool, 1919
The lack of documents after Bill’s marriage makes me wonder why they aren’t included.
The rest of the collection reveals a somewhat different story than I had been told. Bill’s maternal grandparents spent considerably more time in Australia than is suggested by the received narrative that they went to collect their widowed daughter and grandson.
What questions do other family members have?
© Sue Adams 2016
Share this:

Scanning the Bill Lawrence collection
Posted: 14 Nov 2016 Filed under: Sue's family research | Tags: Bill Lawrence collection, digital image format, image quality, image resolution, scanning photgraphs 4 CommentsThe next stage in processing the Bill Lawrence collection, the subject of this series, is scanning. Scanning creates digital copies of documents and photographs. The purposes I envisage for the digital copies of Bill’s collection include:
- Sharing with family members
- Ready accessibility for research
- Examining close-up detail
- Improving legibility
- Reducing wear and tear on the originals
Making digital copies adequate for all these uses within time, cost and equipment constraints requires compromises. So before I start there are some decisions to be made.
Scanning is for access not preservation
One decision that I made while deciding what I intend using the digital copies for is that I am not producing copies for preservation. I frequently see scanning document and photos referred to as a means of preserving them. Scanning does not preserve anything, it makes copies. Paper and photographs only benefit from scanning if they are handled less and suffer less damage as a consequence, because the digital copies are used instead. I also see people suggesting that the original may be discarded once scanned. Even a high quality digital copy is not the same as the original. If it is worth scanning it is worth keeping. Why would you throw a unique original away? I made decisions about what was worth keeping when I catalogued the collection. Paper documents and photographs can be expected to last decades if kept in moderately good conditions (e.g. a room that you live in). In comparison, digital copies are very fragile indeed, and require constant care if they are to remain useable and accessible in the long term. I can replace lost digital copies by re-scanning, but I can’t replace the originals.
My aim is to make working copies, but also pay attention to archival recommendations. My research purposes require good quality images in an accessible format. In the case of this collection, anything that fulfils my needs will likely exceed the expectations of family members, who would be happy with photocopies.
Image Quality
A good quality image for research purposes clearly shows all detail and is faithful to the appearance of the original.
Scanner or digital camera?
It is much easier to achieve consistent image quality using a flat-bed scanner than a digital camera. Scanners have their own light source, a fixed distance between the sensor and target and collect the image data line-by-line by moving the sensor over the target. Consequently images are in focus, of consistent exposure and resolution, and may be very high resolution.
Although digital cameras feature autofocus, automatic exposure and white balance, quality of the image will vary with the light source, camera support and distance from the target. Camera sensors collect all the image data at once, so resolution is limited by the number and size of pixels on the sensor. A handheld camera using ambient light is unlikely to achieve consistent images. Using a camera stand or tripod to set the distance to the target (standardising resolution), and ensure sharp focus; and studio style lighting to standardise exposure and white balance can overcome the difficulties. Some people claim they can digitise more quickly using a camera, but I think this is true only if some quality is sacrificed or the studio is already set up. Claims that apps and mini-studio products convert your phone into a scanner are technically inaccurate. They use the camera in optimal conditions, and may process the images afterward.
There are situations when using a camera is preferable, or the only option. Archives in the UK generally do not allow the use of devices that require contact with the document, which rules out using a portable flat-bed scanner like the popular Flip-Pal or any of the wand or mouse devices. In case you are wondering how that is justified, self-service photocopying is also not allowed. Three dimensional objects, very large documents that don’t fit on a scanner, and documents with features that are difficult to scan well (e.g. watermarks) often warrant careful photography.
Taking account of the equipment I own, my A4 flatbed scanner is the best option for Bill’s collection. Only a few documents need to be scanned in more than two pieces. I don’t own a mini-studio or have practical space to set one up. I may use my digital camera to capture watermarks, and for some creative images.
Resolution
Digital images are made up of pixels, the tiny squares (usually) that you can see if you zoom in enough. Data for each pixel consists of values for constituent colours (Red, Green, Blue) and other properties like brightness. Resolution is measured in pixels per inch or ppi, which is also called dots per inch or dpi. The higher the scanning resolution, the more fine detail is captured.
Archival institutions do not have universal recommendations, but do have similarities. The National Archives (TNA, United Kingdom), British Library (BL) and National Archives and Records Administration (NARA, United States of America) all agree a minimum of 300 ppi for documents. For documents with significant elements of less than 1.5mm, NARA and BL suggest 400 ppi or more. Size matters when it comes to scanning photographs, with smaller photographs needing higher resolutions. TNA suggests a minimum of 600 ppi, BL a range between 300 ppi and 1200 ppi, and NARA between 600 ppi and 2800ppi. Another way of expressing resolution is as the minimum number of pixels along the longest edge of the document. Using this measure NARA suggests 4000 pixels for documents with fine detail and small photographs, and up to 8000 pixels for large photographs. The Smithsonian keeps it simple with a recommendation of at least 6000 pixels along the longest edge for all artefacts.
So, 300 ppi is adequate for most documents in Bill’s collection, and 600 ppi is a good starting point for the photographs. At what resolution would you scan the passport? The most informative pages contain personal details of Robert and Mary Spencer (Bill’s grandparents), small photographs (47mm x 67 mm), ink and embossed stamps, signatures, and a detailed background pattern. Although not strictly necessary for genealogical research, I am fascinated by the anti-forgery features. For genealogical purposes, I need clear representation of stamps, signatures, handwriting and printed information. So the smallest features of interest to me are the background pattern and letters in the embossed stamps (which contain the Royal Arms). After some experimentation, I found 1200 ppi gave me the detail I wanted.
Note that passports are official documents that remain property of the government and parts of this passport, particularly the Royal Arms, might still be subject to Crown copyright. The guidelines for making copies are aimed a current passports. Even though the people are long dead and passports have changed considerably since this passport was issued in 1922, making it very unlikely that copies could now be miss-used, I am going to exercise caution and not publish images of whole pages or the Royal Arms. The photograph of Robert Spencer has been over-stamped in ink. Zooming in on his ear and part of the stamp, an area 10mm high on the original, you can see the effect of resolutions of 300, 600 and 1200 ppi:

Close up of ear in passport photograph at resolutions of 300, 600 & 1200 ppi, shown at the same size. On the right, the relative print size of image extracts with increasing resolution.
Colour and Other Considerations
Depending on the model of scanner there may be a range of settings available. A basic scanner such as the Flip-Pal only has settings for 2 resolutions (300 ppi and 600 ppi). More advanced models have an array of settings including brightness, contrast, colour saturation and balance. NARA offers some sage advice:
“Some people suggest it is best to save raw image files, because no ‘bad’ image processing has been applied. This assumes you can do a better job adjusting for the deficiencies of a scanner or digital camera than the manufacturer, and that you have a lot of time to adjust each image”.
Only if default settings fail to produce an acceptable result will I make any adjustments.
I choose to scan all documents in colour because an authentic copy makes it easier to see different inks in handwriting. Some documents might be more legible scanned as greyscale images. Assessing colour fidelity is difficult because each scanner & digital camera collects the data slightly differently and each computer screen and printer interprets the data differently. Screens come with differing capabilities, so my stand-alone monitor is capable of much greater range in colour and contrast than my basic laptop screen. Calibration of equipment can overcome the technical differences, but remember that no two people see colour the same way. I limit my colour correction to collecting calibration information by scanning a colour reference card (e.g. QPcard) once during a scanning session. Archives may include a colour reference and scale card in each image and calibrate the images after scanning.
Some adjustments are best done during scanning. Printed materials like newspapers and magazines may require adjustment to the de-screening setting, which corrects the moiré pattern that may occur.
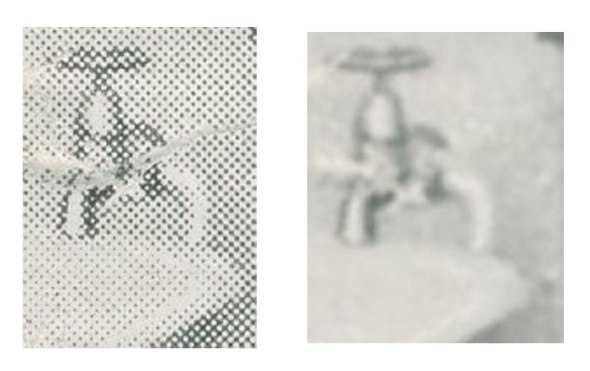
Un-altered close up of a bathroom tap on left, de-screened on right.
Adjustments to contrast can enhance text legibility, especially if the original is faded. This can also be modified using image editing software.

Faded original extract of Bill Lawrence’s birth certificate on left, enhanced contrast on right.
Digital Image Format
Common image file formats produced by scanners include JPEG (Joint Photographic Experts Group, file extension jpg), TIFF (Tagged Image File Format, file extension tif), BITMAP (file extension bmp) and PDF (Portable Document Format, file extension pdf). Each has advantages and disadvantages. Ease of use, quality of image data, preservation of image data, file size and support for image metadata are all considerations.
Many archival institutions use tiff for archival master copies, because it preserves the image data without any loss. JPEG files store the image data in a compressed form that discards some information (known as ‘lossy’ compression). Consequently Tiff files are considerably larger than JPEG files.
For this project I choose to save files as JPEGs, as the small compromise in image quality is outweighed by the ease of use and support for metadata.
Preparation leads to consistency
Having decided on scanning protocols, the images I scan will be consistent quality and suitable for all the purposes I envisage. I also have a starting point for future projects.
My choices for scanning protocols are not the only way of completing a scanning project. You could make different choices because you have different aims and constraints. It is important that you know what decisions you made and why you came to those decisions. Then you are in a good position to keep what works and modify what didn’t in future projects.
© Sue Adams 2016





